







GPUメモリが小さくてもパラメーター数が大きい言語モデルをトレーニング可能になる手法「QLoRA」が登場、一体どんな手法なのか?
GPT-1は1億1700万個のパラメーターを持つ言語モデルで、GPT-2では15億、GPT-3では1750億とパラメーター数が増加するにつれて言語モデルの性能が上がってきています。しかしパラメーター数が増加するにつれてトレーニングに必要なデータの数やトレーニング中に使用するメモリの量も増加し、トレーニングのコストが大きく増加してしまいます。そんな中、メモリの消費量を激減させつつ少ないデータでトレーニングできる手法「QLoRA」が登場しました。
[2305.14314] QLoRA: Efficient Finetuning of Quantized LLMs
https://arxiv.org/abs/2305.14314
artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs
https://github.com/artidoro/qlora
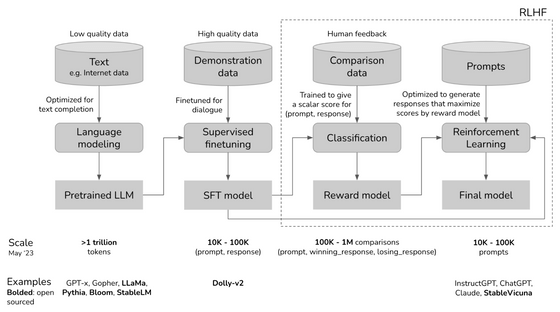
ChatGPTのような大規模言語モデルを作成する際には、まず大量のテキストデータを用いてモデルに「文字の扱い方」を学習させます。こうしてできたモデルが「事前学習済みモデル」と呼ばれるモデルで、代表的な例としてはLLaMaやRedPajama-INCITEが上げられます。その後、Q&Aのお手本など高品質なデータを利用して目的にあった出力を得られるように追加でファインチューニングと呼ばれるトレーニングを行うという流れが一般的です。ファインチューニングだけでもかなり人間らしい返答ができるようになるのですが、より性能を上げるために人間からの評価をモデルにフィードバックする「人間のフィードバックによる強化学習(RLHF)」を行う場合もあります。
モデルのパラメーター数は最初の事前学習を行う段階で決まってしまうため、ファインチューニングなど後の段階で変更することはできません。一般的な企業では事前学習の際に必要な膨大な計算コストを支払うことができないため、公開されている事前学習済みモデルの中からパラメーター数を選択することになります。一般的に、パラメーター数が多いほど性能が高くなりますが、同時にファインチューニングのコストがどんどん高くなっていくという問題が発生していました。
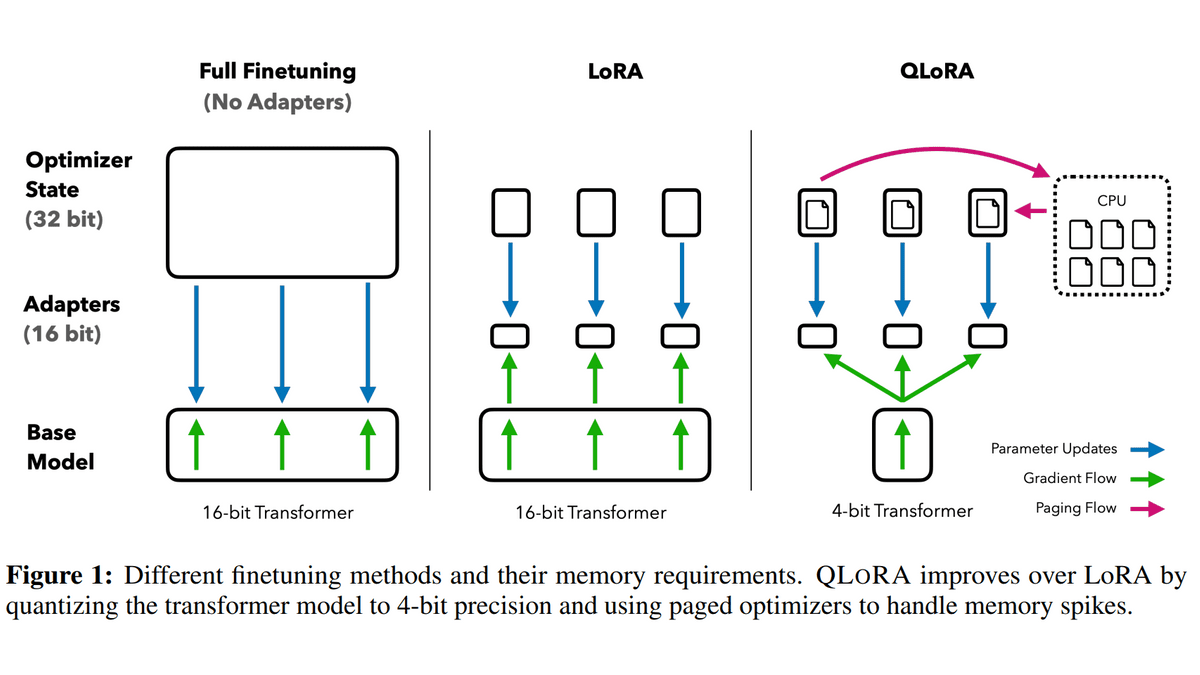
ファインチューニングの際にはモデル全体をメモリに配置する必要があるのはもちろん、トレーニング対象のパラメーターごとに調整のための計算結果をメモリに保存する必要があり、全てのパラメーターを調整対象にする従来のファインチューニングでは元のモデルの何倍ものサイズのメモリを必要とします。例えば、650億(65B)パラメーターのモデルであれば、パラメーター1つにつき16bitで量子化するとモデルをメモリのロードするだけで650億×16bitの130GB分メモリを消費してしまう上に、トレーニングの手法次第ではあるものの650GB程度の計算結果を保存する必要があり、ファインチューニングを行うには合計で780GB分のGPUメモリが必要でした。
こうしたメモリ消費問題を解決するために考案されたのがLoRAというファインチューニングの手法です。LoRAでは、元のモデルのパラメーター行列を低ランク近似した新たな行列をトレーニング対象にすることで、トレーニングに必要なメモリの消費量を削減しています。
[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
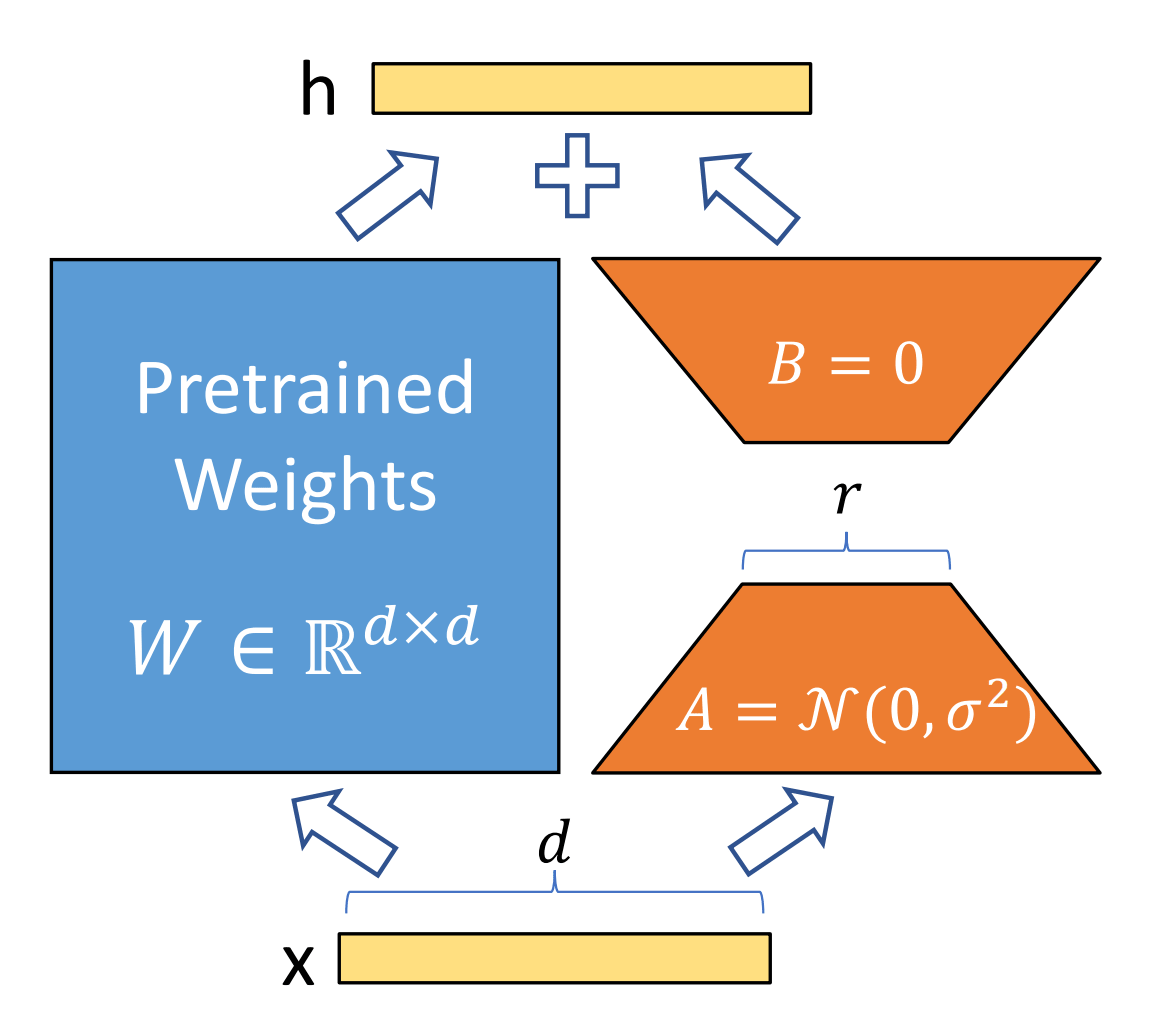
行列を低ランク近似することで、巨大な行列を比較的小さい行列2個に分解可能です。仮に元のモデルのパラメーター行列のサイズが[d]×[d]だった場合、低ランク近似した行列はランク数を[r]として[d]×[r]と[r]×[d]という2つの行列になります。こうすることで、トレーニング対象のパラメーター数をdの2乗個から2×d×r個まで減らすことが可能です。LoRAの論文では、GPT-3のファインチューニングにてトレーニング対象のパラメーター数を1万分の1にし、メモリの消費量を3分の1にしたと述べられています。
LoRAは少ない計算資源で効率よくトレーニングできるため、個人ユーザーの開発意欲が高い画像生成分野において利用が進んでいました。例えばStable Diffusionにおいては、特定の絵柄やキャラクター、背景などをLoRAで学習させることでその学習内容に沿った画像を生成することが可能です。
また、言語モデルの開発においても、計算資源で優位に立っているGoogleの内部ではLoRAを警戒する声が上がっていたことが流出した文章から明らかになっています。
「オープンソースは脅威」「勝者はMeta」「OpenAIは重要ではない」などと記されたGoogleのAI関連内部文書が流出 - GIGAZINE

今回の論文では、このLoRAをベースに、追加で3つのテクニックを利用することで650億(65B)パラメーターのモデルを48GBしかメモリを搭載していないGPUでトレーニング可能にしたうえ、24時間のトレーニングでChatGPTの99.3%に匹敵する性能を引き出すことに成功したとのこと。
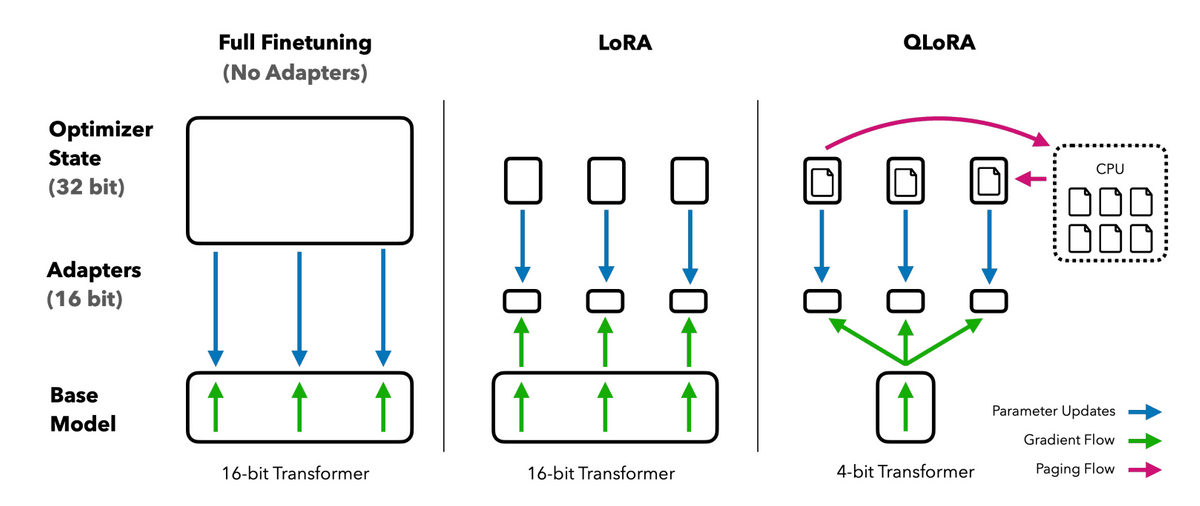
論文で用いられた3つのテクニックは下記の通りです。
・NF4での量子化
一般的に言語モデルの量子化は16bitで行われており、パラメーター1つにつき16bit分の情報が含まれていますが、QLoRAでは代わりに4bitで量子化を行っているとのこと。情報量が低下する分精度も落ちるのですが、通常、事前学習済みモデルのパラメーターは平均が0の正規分布となるため正規分布ベースで量子化を行う「NormalFloat(NF)」形式にすることで精度の低下を抑えています。
・二重量子化
量子化の際に用いる定数についても量子化を行うことで、1パラメーターあたり0.5bit必要だったメモリの消費量を0.127bitへと低下させたとのこと。
・ページ最適化
GPUメモリが上限に達した際に、通常のメモリへとデータを退避させて計算に必要なメモリを確保する手法を利用することで、パラメーターを更新するピーク時のGPUメモリの使用量を抑えることができたとのこと。
Guanaco 33BをQLoRAでトレーニングしたモデルがHugging Face上で試せるようになっています。英語の受け答えしかできませんが、かなり良さげな返答を返すようです。

QLoRAの論文で利用されたコードはGitHubでホスティングされているため、興味がある人は確認してみてください。
・関連記事
グラボ非搭載の低スペックPCでも使える軽量チャットAI「GPT4ALL」の使い方まとめ - GIGAZINE
1600以上のAPIを適切に呼び出してAIに付き物の「幻覚」を大幅に減らす言語モデル「Gorilla」が公開される - GIGAZINE
マインクラフトを大規模言語モデルのGPT-4で反復学習しながら自動でプレイするAIエージェント「Voyager」が登場 - GIGAZINE
無料でノートPCでも実行可能な70億パラメータのチャットボット「GPT4ALL」発表 - GIGAZINE
OpenAIが「言語モデルに言語モデルを説明」させるデモンストレーションツールを公開 - GIGAZINE
・関連コンテンツ






