




「ゼロからGPU開発」に経験なし&わずか2週間で成功した猛者が登場

コードなしでWeb3コンテンツなどを開発することができるプラットフォーム・thirdwebの創設者であるadammaj氏が、「経験なしで2週間でゼロからGPUを構築した」と報告しています。
I've spent the past ~2 weeks building a GPU from scratch with no prior experience. It was way harder than I expected.
— adammaj (@MajmudarAdam) April 25, 2024
Progress tracker in thread (coolest stuff at the end)👇 pic.twitter.com/VDJHnaIheb
◆ステップ1:GPUアーキテクチャの基礎を学ぶ
adammaj氏はまず、最新のGPUがアーキテクチャレベルでどのように機能しているのかを理解しようとしたそうです。GPUは独自性の高い技術であるため、オンライン上にGPUアーキテクチャについて詳細に学べるような学習リソースが存在せず、これは予想以上に困難な作業だった模様。
adammaj氏はNVIDIAのCUDAの学習からスタートし、GPUソフトウェアのパターンを理解しようとしたそうです。これにより、カーネルと呼ばれるGPUプログラムの作成に使用されるSIMDプログラミングパターンを理解することができたとadammaj氏は記しています。
ここからGPUのコア要素について詳細に学習することを決めたというadammaj氏。同氏が学習したGPUのコア要素の概要は以下の通り。
グローバルメモリ:データとそれにアクセスするプログラムを保存する外部メモリは、GPUプログラミングの大きなボトルネックおよび制約となります。
コンピューティングコア:異なるスレッドでカーネルコードを並列実行するメインコンピューティングユニット。
階層化キャッシュ:グローバルメモリへのアクセスを最小限に抑えるためのキャッシュ。
メモリコントローラ:グローバルメモリへのスロットリング要求を処理するためのもの。
ディスパッチャ:実行のために利用可能なリソースにスレッドを分配するGPUのメイン制御ユニット。
さらに、各コンピューティングコア内のメインユニットについても学習しており、adammaj氏が学習したメインユニットの概要は以下の通り。
レジスタ:各スレッドのデータを格納するための専用スペース。
ローカル/共有メモ:スレッド間でデータを受け渡すために共有されるメモリ。
ロードストアユニット(LSU):グローバルメモリからデータを保存/ロードするために使用されるユニット。
コンピューティングユニット:レジスタ値の計算を実行するALU、SFU、専用グラフィックスハードウェアなどの総称。
スケジューラー:各コアのリソースを管理し、異なるスレッドからの命令がいつ実行されるかを計画するユニット。GPUの複雑さの多くはここにあるとのこと。
フェッチャー:プログラムメモリから命令を取得するユニット。
デコーダー:命令を制御信号にデコードするためのユニット。
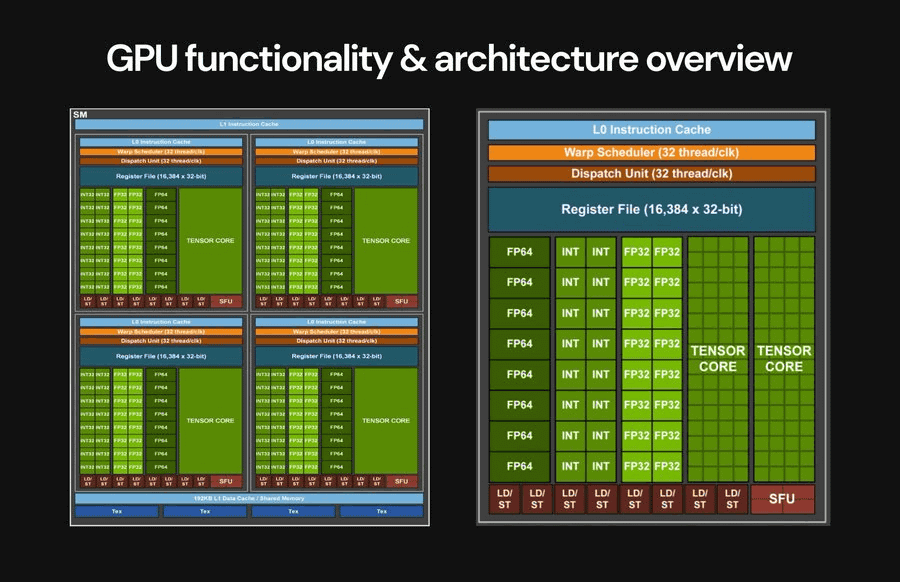
adammaj氏はGPUアーキテクチャの基礎を学習する中で、「GPUは非常に複雑なため、自分の設計に必要なものだけに制限しなければプロジェクトが極端に肥大化してしまうことが分かった」と記しています。
◆ステップ2:独自のGPUアーキテクチャを構築
adammaj氏は学んだことをベースに独自のGPUアーキテクチャの構築をスタート。adammaj氏の目標は「GPUのコア概念を強調し、不要な複雑さを排除し、他の人がGPUについてより簡単に学習できるようにするための最小限のGPUを作成すること」であったため、独自のアーキテクチャを設計することは「本当に重要なことが何かを判断するための素晴らしい練習になった」そうです。
adammaj氏はGPUアーキテクチャの構築において、以下の3点を強調することにしたそうで、「汎用並列コンピューティング(GPGPU)と機械学習(ML)向けのGPUの幅広い使用例を強調したかったので、グラフィック固有のハードウェアではなく、コア機能に焦点を当てることにしました」と説明しています。
並列化:SIMDパターンはハードウェアでどのように実装されるのか?
メモリアクセス:GPUは低速で帯域幅が制限されたメモリから大量のデータにアクセスするという課題にどのように対処するのか?
リソース管理:GPUはどのようにしてリソースの使用率と効率を最大化するのか?
こうしてadammaj氏が独自に構築したGPUアーキテクチャが以下。同氏は「何度も繰り返して、最終的に実際のGPUに実装したアーキテクチャにたどり着きました」と説明。なお、以下の図ではGPUアーキテクチャが最も単純な形式で表記されています。

◆ステップ3:GPU用にカスタムアセンブリ言語を作成
最も重要なことは「GPUがSIMDプログラミングパターンで記述されたカーネルを実際に実行できるかどうか」です。これを可能にするために、カーネルの作成に使用できる独自の命令セットアーキテクチャ(ISA)をGPU用に設計する必要があった模様。
そのため、adammaj氏はISAのひとつである「LC4」からヒントを得て、独自設計のISAを構築。さらに、概念実証としていくつかの簡単な行列計算カーネルを記述できるようにしたそうです。
adammaj氏が独自設計したISAの正確な構造とエンコーディング内容をまとめた表が以下。

◆ステップ4:ISAを利用して行列計算カーネルを記述
独自のISAができたので、続いてGPUで実行する2つの行列計算カーネルを作成。各カーネルは操作する行列、起動スレッドの数、各スレッドで実行するコードなどを指定します。
adammaj氏の作成した行列加算カーネルは、8つのスレッドを使用して2つの1×8行列を加算し、SIMDパターン、いくつかの基本的な算術命令、ロード/ストア機能の使用方法を示します。また、同氏は行列乗算カーネルも作成しており、このカーネルでは3つのスレッドを使用して2つの2×2行列を乗算し、分岐とループを示すことができるように設計されているそうです。
adammaj氏は「グラフィックスと機械学習の両方における最新のGPU使用事例を踏まえると、行列計算(はるかに複雑なカーネルを使用)を中心に展開されているため、行列計算機能のデモンストレーションは重要でした」と語っています。
adammaj氏が作成した行列加算カーネルと行列乗算カーネルは以下の通り。

◆ステップ5:VerilogでGPUを構築してカーネルを実行
その後、VerilogでGPUの設計をスタート。これについてadammaj氏は「間違いなく最も困難な作業で、多くの問題に遭遇しながらコードを何度も書き直すことになりました」と語っています。
adammaj氏は複数回のコードの書き直しを通じ、「メモリの問題に遭遇した時、ボトルネックとなっているメモリからのアクセスを管理することがGPUの最大の制約のひとつである理由を実感しました」「複数のLSUが同時にメモリにアクセスしようとしたために設計通りに機能せず、リクエストキューシステムが必要であることに気づきました。この時、メモリコントローラーの必要性を根本から理解することができました」「ディスパッチャ/スケジューラーにシンプルなアプローチを実装したところ、パイプラインなどのより高度なスケジューリングとリソース管理戦略によってパフォーマンスを最適化できることがわかりました」などと記しました。
以下はVerilogでGPUに組み込んだ単一スレッドの実行フローです。
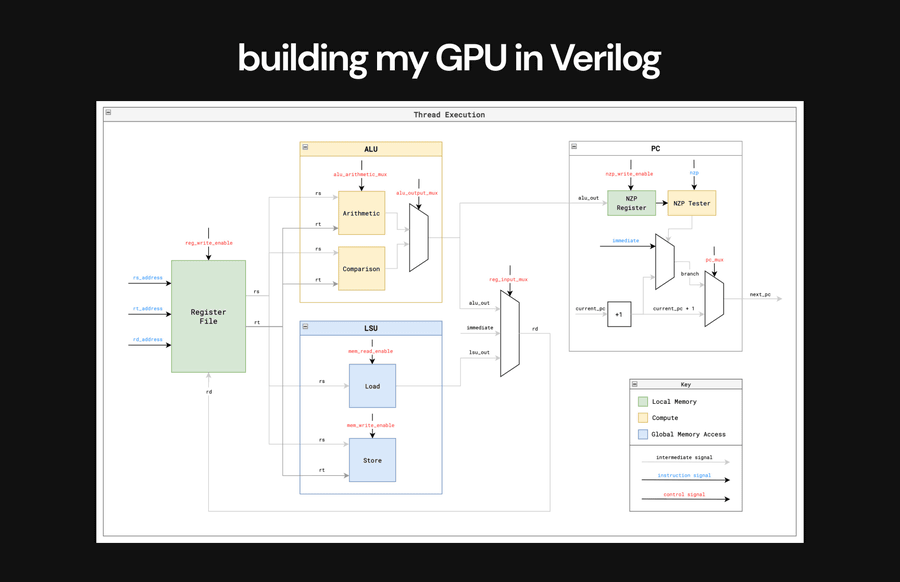
以下の動画はGPU上で行列加算カーネルを実行し、実行中のGPUの実行トレースを調べ、GPUが最終結果を保存したデータメモリの終了状態を確認する様子を収めたもの。実行トレース内の各サイクルで、各スレッドおよびコアの個々の命令、PC、ALU 処理、レジスタ値などを確認可能です。adammaj氏は「最も重要なのは、最初に結果のマトリックスの空アドレスが表示され、最後に正しい値がデータメモリ内の結果のマトリックスにロードされることです」と記しています。
After tons of redesigns, finally running my matrix addition & multiplication kernels and seeing things work properly and my GPU output the correct results was an incredible feeling.
— adammaj (@MajmudarAdam) April 25, 2024
Here's a video of me running the matrix addition kernel on my GPU, going through the execution… pic.twitter.com/WB6PqblK31
◆ステップ6:デザインをフルチップレイアウトに変換
Verilogでの設計が完了したら、最後のステップとして設計をEDAフローに渡し、最終的なチップレイアウトを作成します。プロセスノードは半導体メーカーSkywaterの「130nm」を採用し、Tiny Tapeout 6で製造しました。
理論上およびシミュレーション上で機能する設計があるかもしれませんが、その設計をGDSファイルを使用して最終的なチップレイアウトに変換することは、「設計を出荷する際の大きな障壁となります」とadammaj氏。実際、OpenLaneで指定された設計ルールをクリアすることができないという問題が発生し、問題を解決するためにGPU設計の一部を修正する必要があったとadammaj氏は語っています。
adammaj氏が作成したGPUのチップレイアウトは以下の通り。

なお、adammaj氏によるGPU開発の詳細はGitHub上でもまとめられています。
GitHub - adam-maj/tiny-gpu: A minimal GPU design in Verilog to learn how GPUs work from the ground up
https://github.com/adam-maj/tiny-gpu


・関連記事
NVIDIAの「CUDA」とIntelのGPUをつなぐソフトウェア「ZLUDA」がAMD向けとして転身復活するも今後の開発は絶望的 - GIGAZINE
NVIDIAが数兆パラメータ規模のAIモデルを実現するGPUアーキテクチャ「Blackwell」と新GPU「B200」を発表 - GIGAZINE
GPUを開発・製造する企業は全世界で19社、PCやデータセンター向けGPUを設計する11社のうち8社が中国に拠点を置いている - GIGAZINE
NVIDIAのAI特化GPUは一体どんなものなのか?ゲーム用GPUとは別物なのか? - GIGAZINE
・関連コンテンツ







